


 cs
cs 



Když IT týmy poprvé uvidí Analytics Plus, často si řeknou: „Reporty už ve svých nástrojích máme. Proč potřebujeme ještě tohle?“
Hlavní myšlenka je jednoduchá: Analytics Plus není jen o reportech. Je to analytická vrstva pro celé vaše IT prostředí. Přivádí data z mnoha IT nástrojů na jedno místo, abyste mohli odpovídat na otázky, na které žádný jednotlivý nástroj sám odpovědět neumí.
Tento článek je určen zákazníkům, kteří už Analytics Plus používají (nebo ho plánují) a chtějí ho navrhnout jako plnohodnotnou analytickou platformu, ne jen jako „hezký extra dashboard“.
Probereme:
- Co Analytics Plus ve skutečnosti je
- Proč začínat otázkami, a ne tabulkami
- Tři hlavní oblasti dashboardů, které má smysl budovat
- Obnovu dat, výkon a kvalitu dat
- Sdílení a governance (kdo co vidí)
- Využití AI a dotazů v přirozeném jazyce
- Závěrečný checklist pro dobře nastavené Analytics Plus
Nejsou tu rollout plány, jen koncepty, které si můžete přizpůsobit vlastnímu prostředí.
Co Analytics Plus ve skutečnosti je
Z pohledu produktu je Analytics Plus BI (business intelligence) platforma zaměřená na IT.
Jednoduše řečeno vám pomáhá:
- Stahovat data z mnoha zdrojů: IT nástrojů, souborů, databází, cloudových aplikací a produktů ManageEngine.
- Propojovat datové sady mezi sebou (definovat vztahy mezi tabulkami).
- Stavět reporty a dashboardy pomocí drag-and-drop.
- Obnovovat data podle plánu a posílat reporty e-mailem nebo jako alerty.
- Pokládat dotazy v běžném jazyce pomocí vestavěných AI funkcí.
Mnoho zákazníků propojuje Analytics Plus s produkty jako ServiceDesk Plus, ServiceDesk Plus Cloud, ServiceDesk Plus MSP, OpManager, Applications Manager, Endpoint Central, AssetExplorer a dalšími. Díky tomu se Analytics Plus stane jedním místem, kde vidíte data napříč celým IT prostředím.
Klíčová myšlenka tedy je: Analytics Plus je „jeden zdroj pravdy“ pro IT data, ne jen další nástroj na reporty jednoho produktu.
Začínejte otázkami, ne tabulkami
Častá chyba vypadá takto: „Připojme ServiceDesk Plus do Analytics Plus a uvidíme, jaké reporty z toho vypadnou. “Nějakou rychlou hodnotu to přinese, ale nevyužije to plný potenciál platformy.
Lepší přístup je: Začněte otázkami z byznysu a IT. Až pak navrhujte datový model a dashboardy tak, aby na tyto otázky odpovídaly.
Sbírejte reálné otázky od stakeholderů
Mluvte s lidmi, kteří vlastní procesy a služby: vedoucí service desku, šéf infrastruktury, bezpečnostní manažer, vlastníci aplikací atd. Zeptejte se jich: „Na jaké otázky dnes neumíme odpovědět, nebo umíme jen přes Excel?“
Příklady dobrých „cross-tool“ otázek:
- Které služby generují nejvíce tiketů a zároveň nejvíce výpadků?
(Potřebujete data ze ServiceDesk Plus a monitoringu, např. OpManager nebo Applications Manager.) - Které lokality mají nízký patch compliance a zároveň vysoký počet incidentů?
(Potřebujete Endpoint Central, ServiceDesk Plus a případně CMDB nebo data z AssetExploreru.) - Dostávají VIP uživatelé rychlejší reakci a vyřešení než ostatní?
(Potřebujete data o ticketech, o uživatelích – oddělení, VIP příznak – a data o SLA.)
Pro každou otázku si zapište, z jakých nástrojů a jaký typ dat budete potřebovat.
Namapujte otázky na tabulky a pole
V Analytics Plus jsou importovaná data uložena v tabulkách se sloupci (poli). Každá integrace (např. ServiceDesk Plus) přináší několik tabulek, jako Requests (požadavky), Technicians (technici), Departments (oddělení) atd. Pro každou otázku si určete:
- Hlavní „faktovou“ tabulku
Například Requests ze service desku, Alarms z monitoringu, Patches z endpoint managementu. - Související „lookup“ tabulky
Například Technicians, Users, Sites, Departments, Assets, Services, Changes. - Klíčová pole pro joiny a filtry
ID ticketu, ID zařízení, lokalita/site, oddělení, kategorie, priorita, stav, čas vytvoření, čas vyřešení atd.
Když si toto mapování uděláte předem, práce v Analytics Plus je mnohem jednodušší. Když to přeskočíte, strávíte spoustu času opravou joinů a vzorců.
Definujte vztahy v Analytics Plus
Pak otevřete datový model v Analytics Plus a nastavte vztahy mezi tabulkami.
Zjednodušeně přemýšlejte takto:
- Jedna hlavní faktová tabulka: tikety, alarmy, patche nebo podobná událostní data.
- Několik lookup tabulek: uživatelé, zařízení, lokality, služby, oddělení.
- Každý vztah by měl být jasně „one-to-many“ nebo „many-to-one“. Například jedno oddělení má mnoho tiketů; jedna lokalita má mnoho zařízení; jedno zařízení může mít mnoho tiketů.
Dávejte pozor na to, aby:
- ID a klíče odpovídaly (např. stejné ID zařízení v tabulce tiketu i v tabulce assetů).
- Nevznikaly zbytečné nebo kruhové joiny.
- Každá tabulka měla jasný účel (žádné duplicity).
Čistý datový model je základ pro jakoukoliv vážně míněnou analytiku.
Základní dashboardy pro IT provoz
Možností dashboardů je nekonečně, ale téměř každý vyspělejší IT tým těží minimálně ze tří hlavních oblastí:
- Spolehlivost service desku
- Soulad a rizika na koncových zařízeních
- Zdraví sítě a aplikací
Tyto koncepty si můžete rozšířit a přizpůsobit podle svého prostředí.
Dashboard spolehlivosti service desku
Cíl: Vidět, zda je váš service/help desk spolehlivý, rychlý a předvídatelný.
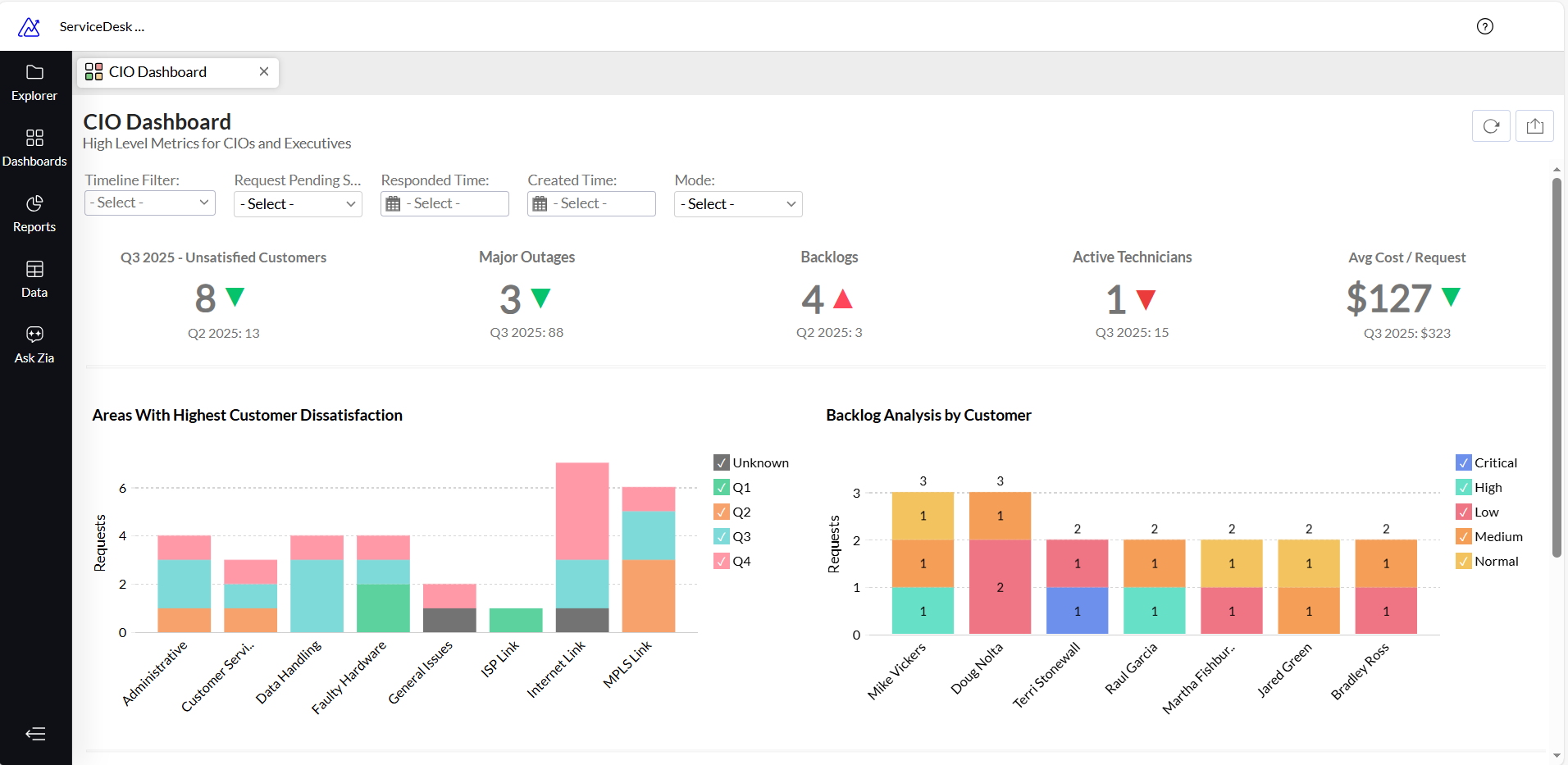
Zdroje dat:
- ServiceDesk Plus (on-prem nebo cloud) nebo ServiceDesk Plus MSP.
- Volitelně další zdroje (např. HR systém nebo CMDB), pokud chcete více kontextu.
Klíčové metriky (v jednoduché logice):
- Vývoj počtu vytvořených vs. vyřešených tiketů v čase
Zobrazte po dnech nebo týdnech. Sledujte rozdíl mezi vytvořenými a vyřešenými tikety a zjistěte, zda backlog roste, nebo se zmenšuje. - Soulad se SLA
Procento tiketů, kde čas vyřešení nastal před nebo v čase SLA due time. Můžete zobrazit podle služby, lokality, priority nebo technika. - Míra opětovného otevření (reopen rate)
Počet znovu otevřených tiketů dělený počtem vyřešených tiketů. Vysoká hodnota může ukazovat na nekvalitní řešení nebo špatnou komunikaci. - Vyřešení při prvním kontaktu
Tikety vyřešené při první odpovědi, bez dalšího reopen. Ukazuje, kolik problémů je vyřízeno rychle, bez dlouhé ping-pong komunikace. - Užitečné rozpadové pohledy:
Podle kategorie, podkategorie nebo služby
Pomáhá vidět, které služby nebo typy problémů jsou „hlučné“ a vyžadují problem management. - Podle technika nebo skupiny
Ukazuje vytížení, výkonnost a oblasti, kde tým může potřebovat podporu nebo školení. - Podle lokality, země nebo byznys jednotky
Překládá IT metriky do jazyka byznysu, aby manažeři viděli dopad na „svou“ část firmy.
Pokročilá, ale stále čitelná vylepšení:
- Používejte pracovní (business) hodiny vs. kalendářní hodiny pro reakci a vyřešení. Pracovní hodiny ukazují reálný pracovní čas; kalendářní hodiny celkovou prodlevu z pohledu uživatele.
- Přidejte VIP příznak z tabulky uživatelů a porovnejte výkon SLA pro VIP uživatele vs. ostatní. Pomůže to ověřit, zda kritičtí uživatelé dostávají zvláštní péči.
Dashboard souladu a rizik koncových zařízení
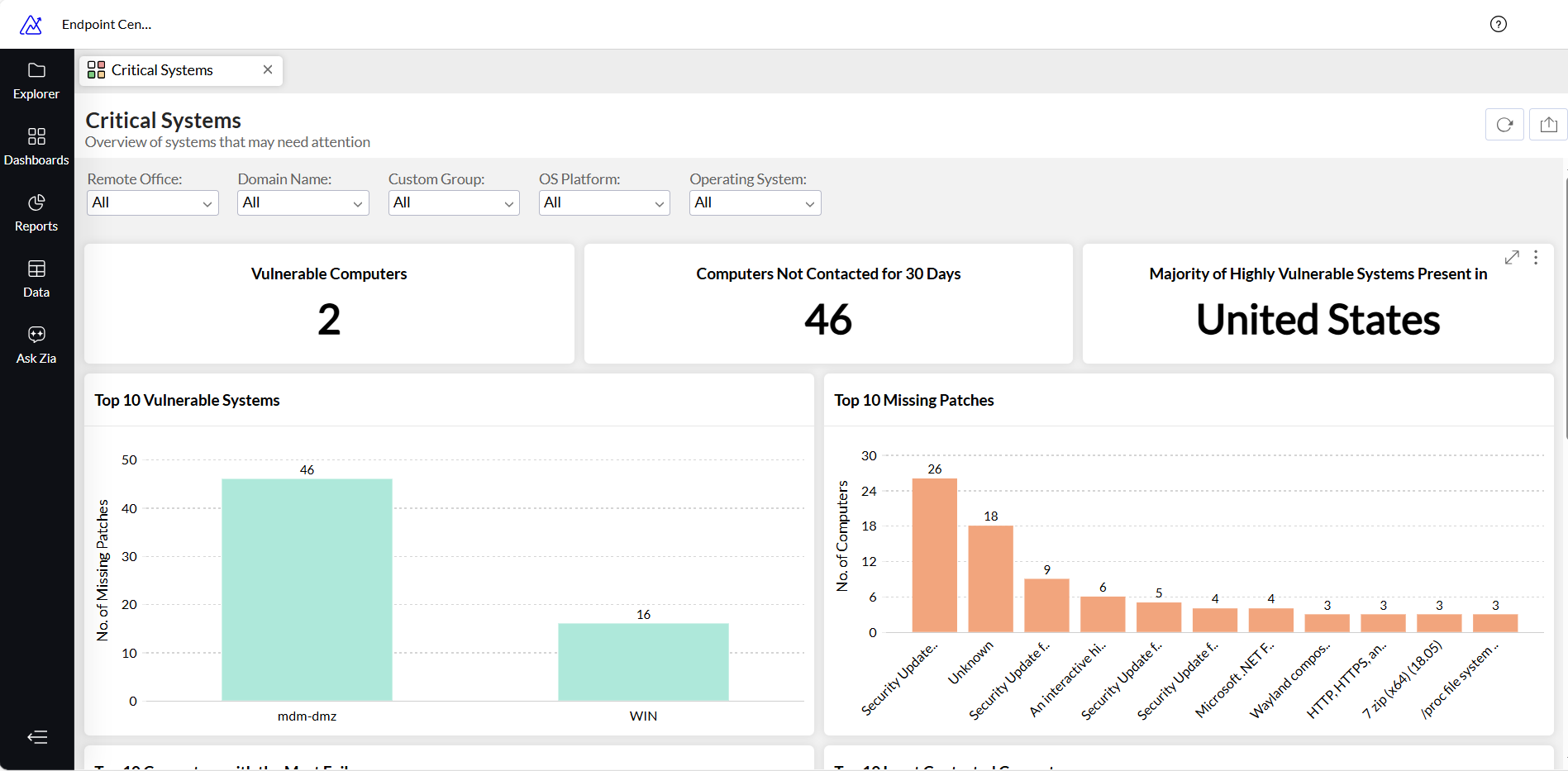
Cíl: Vidět aktuální riziko z pohledu koncových zařízení: chybějící patche, nepodporované operační systémy a slabé bezpečnostní nastavení.
Zdroje dat:
- Endpoint Central nebo podobný nástroj pro endpoint management (stav patchů, verze OS, stav agenta, čas posledního kontaktu).
- ServiceDesk Plus nebo jiný ticketovací systém (incidenty související s patchováním, antivirem, výkonem atd.).
Klíčové metriky:
- Patch compliance
Například:
o Procento zařízení, která mají nainstalované všechny bezpečnostní patche za posledních X dní.
o Procento zařízení, kterým chybí alespoň jeden kritický patch. - Seznam vysoce rizikových zařízení
Tabulka zařízení, která splňují některé z těchto pravidel:
o Mají kritické zranitelnosti.
o Běží na nepodporovaném OS (např. verze Windows bez rozšířené podpory).
o Byla offline déle než zvolený počet dní. - Incidenty vs. compliance
Např.: spočítejte tikety týkající se nestabilních nebo infikovaných zařízení a zjistěte, kolik z nich je zároveň nekompatibilních / nevyhovujících politikám. Díky tomu uvidíte skutečný dopad špatného patchování nebo chybějících kontrol.
Užitečné rozpady:
- Podle lokality nebo site
Pomáhá najít pobočky s nízkým patch compliance nebo velkým počtem rizikových zařízení. - Podle byznys služby nebo aplikace
Pokud máte zařízení namapovaná na služby či aplikace, můžete vytvořit pohled „riziko na službu“. - Podle role zařízení
Servery, pracovní stanice, pokladní systémy (POS), kiosky atd. Umožní vám aplikovat jiné prahy a priority pro různé typy zařízení.
Dashboard zdraví sítě a aplikací
Cíl: Propojit monitorovací data (síť, servery, aplikace) s tikety a změnami a vidět celý životní cyklus incidentů a výpadků.
Zdroje dat:
- OpManager, Applications Manager nebo jiné monitorovací nástroje (alarmy, performance eventy, dostupnost, odezvy).
- ServiceDesk Plus nebo jiný ITSM nástroj (incidenty a změny).
- Volitelně CMDB nebo asset data pro topologii a vlastnictví.
Klíčové metriky:
- Top zařízení nebo služby podle počtu alarmů
Ukazuje, které komponenty jsou „hlučné“ a způsobují alert fatigue. - Dostupnost a výpadky
Procento uptime a celková doba výpadků v daném období. Můžete zobrazovat podle zařízení, služby nebo lokality. - Mean Time To Repair (MTTR)
Průměrná doba od prvního alarmu do plného obnovení služby. Můžete měřit podle služby, lokality nebo týmu. - Mean Time To Ticket (MTTI)
Čas od vzniku alarmu do vytvoření incidentního ticketu. Ukazuje, jak rychle se monitorovací eventy mění na oficiální záznamy a workflow. - Dopad změn (Change impact)
Počet alarmů a incidentů v hodinách nebo dnech po provedení změny. Odhalí rizikové změny a pomáhá zlepšovat change management.
Užitečné pohledy:
- Kombinovaná časová osa
Graf, kde jsou na jedné časové ose alarmy, tikety i změny. Snadno pak uvidíte, zda výpadek následoval po změně, nebo zda alarmy běžely dlouho před otevřením ticketu. - Mapa zdraví lokalit
Jednoduchá tabulka nebo vizualizace, kde je každá lokalita označena jako zelená/žlutá/červená podle dostupnosti, počtu alarmů a incidentů. - „Flapping“ zařízení
Seznam zařízení, která často přecházejí mezi stavem up/down. Způsobují šum v alarmech a mohou zakrývat skutečné problémy.
Obnova dat, výkon a kvalita dat
Krásný dashboard se starými nebo špatnými daty je horší než žádný dashboard. Pro vážné použití musíte navrhnout, jak se data přesouvají, obnovují a kontrolují.
Chytrá obnova dat
V Analytics Plus můžete nastavit, jak často se který zdroj dat obnovuje, a také spouštět obnovu ručně. Frekvenci volte podle toho, jak se daná data používají:
- Management a strategické dashboardy:
Často stačí denní nebo hodinová obnova. Tyto dashboardy ukazují trendy, ne realtime provoz. - Operativní dashboardy (NOC, wallboardy na service desku):
Můžou potřebovat refresh každých pár minut, pokud to velikost dat a prostředí zvládne.
Kde to jde, používejte inkrementální import místo plného. Analytics Plus pak tahá jen nová nebo změněná data od posledního běhu, což je rychlejší a méně náročné.
Práce s velkým objemem dat
Analytics Plus je navržený pro velké objemy dat z více nástrojů, ale dobrý návrh je pořád důležitý.
Praktické tipy:
- Omezuje, kolik detailní historie držíte v jednom workspace.
Například plné detailní tikety za 1–2 roky a starší data agregujte do měsíčních nebo kvartálních souhrnných tabulek. - Vyhýbejte se reportům, které spojují najednou mnoho obrovských tabulek.
Raději si udělejte mezitabule s předagregovanými daty a na nich stavte dashboardy. - Používejte filtry v dashboardech.
Dejte uživatelům možnost filtrovat podle data, lokality, služby nebo jiných dimenzí, místo aby se vždy načítala „veškerá data“.
Kvalita dat a „Data Health“ dashboard
Kvalita dat není jen o technických chybách. Patří sem i chybějící pole, špatné mapování a nekonzistentní pojmenování. Analytics Plus můžete použít i na sledování kvality dat samotné.
Nápady na data health dashboard:
- Pro každý zdroj zobrazte čas poslední úspěšné synchronizace a počet naimportovaných řádků.
- Spočítejte tikety s chybějící kategorií, technikem nebo lokalitou/site.
- Spočítejte zařízení bez lokality, oddělení nebo přiřazené služby.
- Zobrazte procento záznamů s neplatnými nebo prázdnými klíčovými poli.
Tento dashboard obvykle používá admin Analytics Plus nebo správce dat (data steward). Pomáhá najít a opravit problémy dříve, než se projeví v „byznys“ dashboardech pro management.
Sdílení a governance: kdo co vidí
Jakmile se Analytics Plus stane kritickým nástrojem, bude do něj chtít přístup mnoho lidí. Musíte proto navrhnout role a oprávnění tak, aby každý viděl jen to, co vidět má.
Jednoduchý model rolí:
- Viewer
o Business manažeři a vlastníci služeb.
o Mohou prohlížet dashboardy a filtrovat je, ale nemohou je měnit. - Analyst
o Vlastníci procesů a „power users“ z IT.
o Mohou vytvářet a upravovat reporty a dashboardy ve sdílených workspacích. - Admin
o Administrátoři Analytics Plus.
o Spravují zdroje dat, harmonogramy, workspace a přístupy uživatelů.
K tomu možná budete potřebovat i zabezpečení na úrovni dat:
- Oddělení workspace
Například jeden workspace pro obecný IT provoz a zvlášť workspace pro bezpečnostní eventy nebo data související s HR. - Filtrování na úrovni řádků (row-level security)
Omezuje přístup k záznamům podle lokality, země nebo oddělení. Například regionální manažer vidí jen tikety ze svého regionu.
Tento návrh by měl být v souladu s firemními politikami pro řízení přístupu, audit a ochranu soukromí.
AI a dotazy v přirozeném jazyce
Jednou z nejsilnějších nových oblastí v Analytics Plus je možnost pokládat dotazy v přirozeném jazyce.
Uživatel může napsat například: „Show open high-priority tickets by site for last 7 days“
Analytics Plus se pokusí otázce porozumět, najít správné tabulky a pole a automaticky vytvoří report nebo graf.
To je obzvlášť užitečné pro uživatele, kteří:
- Vědí, co chtějí vidět, ale neumí postavit složitý report.
- Potřebují rychlé jednorázové pohledy (ad-hoc dotazy).
- Chtějí data prozkoumávat, aniž by čekali na tým reportingu.
Několik jednoduchých pravidel pomůže:
- Pište srozumitelné otázky: uveďte metriku (např. počet tiketů), filtr (např. otevřené, s vysokou prioritou) a dimenzi (např. podle lokality/site).
- Když vám nástroj vygeneruje report, který se vám líbí, uložte si ho a ručně doladěte: popisky, vzorce, řazení, formátování.
- Klíčové uživatele vytrénujte v obou směrech: jak pokládat dobré otázky a jak upravovat či opravovat AI-generované reporty.
AI funkce nenahrazují dobrý datový model. Nejlépe fungují právě tehdy, když stojí na čistém a dobře strukturovaném datovém modelu.
Závěrečný checklist
Tento checklist můžete použít jako rychlý přehled, jak zralé je vaše prostředí Analytics Plus:
- Máme sepsané hlavní IT a byznys otázky, na které chceme odpovídat – ne jen seznam reportů, které chceme překlopit.
- Víme, jaké zdroje dat a tabulky jsou potřeba pro každou otázku.
- Máme jasný datový model: faktové tabulky, lookup tabulky a čisté vztahy.
- Máme alespoň tři základní dashboardy:
o Spolehlivost service desku
o Soulad a rizika na koncových zařízeních
o Zdraví sítě a aplikací - Obnovu dat máme nastavenou s rozumnými harmonogramy pro každý zdroj.
- Máme způsob, jak sledovat kvalitu dat (např. data health dashboard).
- Máme definované role a pravidla sdílení a tato pravidla jsou v platformě nastavená.
- Klíčoví uživatelé vědí, jak používat AI a dotazy v přirozeném jazyce pro rychlé průzkumy.
Pokud pro většinu těchto bodů platí „ano“, pak Analytics Plus jen „nepoužíváte“. Budujete skutečnou IT analytickou vrstvu, která může podporovat rozhodování napříč celou organizací.
15.12.2025
Autor: Luboš Pham
Kategorie: Články

Luboš Pham
Technický Konzultant


