



 pl
pl 




Kolejnym wyzwaniem, które wprowadza Ustawa o Krajowym Systemie Cyberbezpieczeństwa jest monitorowanie usług kluczowych. W poprzednim artykule zostały opisane rozwiązania pozwalające na monitorowanie zdarzeń. Tym razem analizujemy, co dokładnie kryje się pod pojęciem monitoringu usług kluczowych oraz w jaki sposób wykonywać to zadanie poprawnie.
Zapisy zawarte w ustawie mają jedynie nakierować nas na to, czym jest monitorowanie usług kluczowych, nie definiując jednak bezpośrednio samej czynności.
Przytoczmy fragmenty ustawy, opisujące nasze wyzwanie, by lepiej je zrozumieć:
- bezpieczeństwo i ciągłość dostaw usług, od których zależy świadczenie usługi kluczowej
– Art.8, podpunkt 2c - […]dokumentowanie i utrzymywanie planów działania umożliwiających ciągłe i niezakłócone świadczenie usługi kluczowej[…]
– Art.8, podpunkt 2d - objęcie systemu informacyjnego wykorzystywanego do świadczenia usługi kluczowej systemem monitorowania w trybie ciągłym
– Art.8, podpunkt 2e
Fragmenty opisują monitorowanie na warstwie sprzętowej oraz aplikacyjnej.
Nie mówią dokładnie, które elementy należy monitorować. Postaramy się wyjaśnić tę kwestię. Każda nowoczesna aplikacja/usługa jest zależna od wielu systemów, z których korzysta. Bez nich, przestałaby działać poprawnie.
Elementami, z których może korzystać usługa kluczowa, pod względem infrastruktury fizycznej mogą być:
- Serwery fizyczne,
- Maszyny wirtualne,
- Interfejsy sieciowe,
- Routery,
- Access Pointy,
- VLAN’y,
- Firewalle.
Jednak warstwa fizyczna nie jest wszystkim, co należy weryfikować. Pod uwagę musimy również wziąć warstwę aplikacji, w tym jej wszystkie składowe komponenty, takie jak:
- Serwery WWW,
- Serwery bazodanowe,
- Zewnętrzne usługi API,
- Serwery pocztowe,
- Pozostałe usługi, takie jak:
- LDAP/Active Directory,
- DNS,
- DHCP.
Dlatego ważnym zadaniem każdego dostawcy jest ich monitorowanie oraz weryfikacja ciągłości działania.
Możemy wyobrazić sobie podstawową sytuację, w której to baza danych przestaje działać. Nie możemy odpytać jej o żaden zbiór danych lub zapisać nowych. W wyniku takiej sytuacji, nasza usługa kluczowa przestaje funkcjonować poprawnie, co skutkuje jej niedostępnością. Bez odpowiedniego monitorowania komponentów podrzędnych, nie jesteśmy w stanie efektywnie weryfikować poprawnego działania.
Oczywiście możemy weryfikować ją poprzez prosty schemat. Za przykład posłuży nam strona internetowa, która pobiera personalne dane użytkownika i przekazuje je do urzędu. Potraktujmy to, jako usługę kluczową.
Możemy monitorować dostępność strony i jej czas odpowiedzi. Jednak nie pozwoli nam to ustalić przyczyny wystąpienia awarii w szybki sposób. Problemem mógłby okazać się Switch, Router, Serwer Bazodanowy lub interfejs sieciowy.
Wyobraźmy sobie inną sytuację, w której to strona Internetowa działa poprawnie. Jednak czasy jej odpowiedzi przekraczają ustalone przez nas wartości. W takim przypadku musimy przeanalizować wszystkie składowe w poszukiwaniu wąskiego gardła, które spowodowało problem.
Wyzwaniem dla nas jest zabezpieczenie się przed takimi i innymi tego typu sytuacjami, poprzez monitorowanie wszystkich usług głównych, jak i podrzędnych, w celu minimalizacji czasu naprawy.
Naszą propozycją jest zestaw dwóch aplikacji:
– narzędzie monitorujące całą warstwę sprzętową
– narzędzie monitorujące warstwę aplikacyjną oraz usługi kluczowe i podrzędne.
Obie te aplikacje mogą działać osobno lub razem, poprzez zintegrowanie ich do poziomu jednej konsoli, co ułatwi cały proces konfigurowania monitorowania usług kluczowych.
Rozpocznijmy od monitorowania warstwy sprzętowej.
Nasza aplikacja pozwala na monitorowanie wielu urządzeń fizycznych. Lista wspieranych urządzeń ciągle się powiększa, dzięki zaangażowaniu użytkowników oraz producenta, który implementuje ich obsługę.
Za przykład weźmiemy serwer oparty o Windows’a. Z poziomu interfejsu graficznego podgląd urządzenia wygląda następująco:
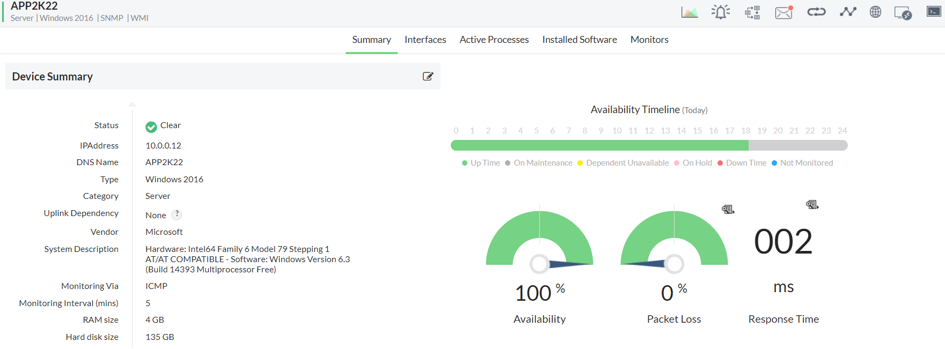
Prezentuje on wszystkie podstawowe informacje dotyczące naszego serwera, rozpoczynając od adresacji IP, kończąc na pamięci RAM. Widzimy również czasy dostępności oraz czas odpowiedzi na PING. Warto dodać, że możemy również widzieć w tym miejscu inne monitory, które są dla nas kluczowe.
Aplikacja weryfikuje również interfejsy sieciowe, z których pobierane są aktualne dane.
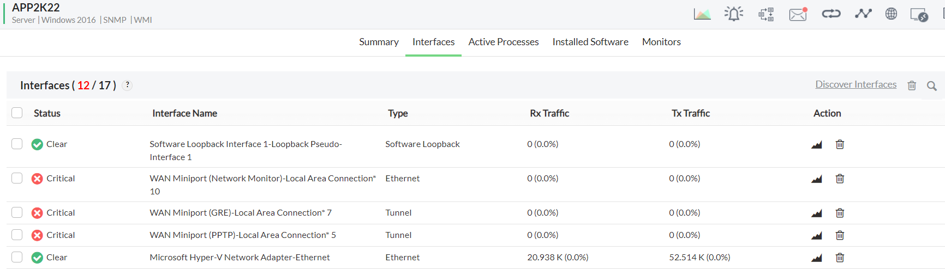
Na zrzucie ekranu widzimy:
- Status interfejsu – określany poprzez statusy: Clear, Attention, Trouble, Critical. Są to poziomy krytyczności, ustalane na podstawie wartości brzegowych,
- Nazwę interfejsu,
- Typ interfejsu,
- Transfer wychodzący/przychodzący.
Jedną z ważniejszych pozycji są monitory, które pozwalają na skonfigurowanie wartości brzegowych, w oparciu o pobierane dane. Dzięki temu możemy monitorować konkretne aspekty naszego urządzenia.
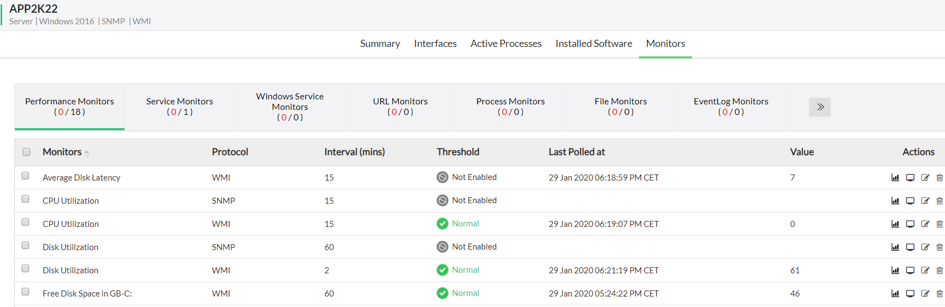
W tej zakładce są prezentowane tak zwane „monitory” do naszego urządzenia, które cyklicznie są aktualizowane. Również z tego poziomu, możemy dostosować wartości brzegowe do takich, które spełnią nasze założenia.
Przejdźmy zatem do modyfikacji przykładowego monitora:
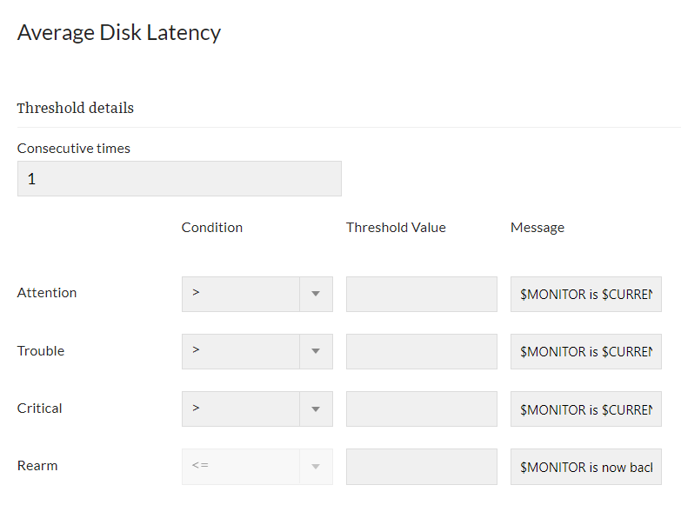
Z tego poziomu możemy ustawić wartości specyficzne dla naszego urządzenia, które w przypadku przekroczenia, wyzwolą alarm informujący administratora o zaburzonym działaniu monitora lub jego niedostępności, co może przełożyć się na problem z dostępnością usługi kluczowej. System obsługuje wiele typów akcji, które mogą zostać użyte, są to m.in.:
- Wiadomości e-mail,
- Wiadomości SMS,
- Wykonanie skryptu/programu,
- Wykonanie workflow.
Wartości brzegowe mogą być specyficzne dla urządzenia lub też ogólne. Ogólne wartości możemy konfigurować pod wstępnie przygotowanymi szablonami, dla danego typu urządzenia. Pozwalają one na wstępną konfigurację wszystkich parametrów. Szablony są nakładane automatycznie, po wykryciu odpowiedniego typu urządzenia. Dzięki tym szablonom możemy przypisać podstawowe monitory, które będą przykładowo weryfikować, czy ilość wolnego miejsca jest większa niż 15% całkowitej pojemności.
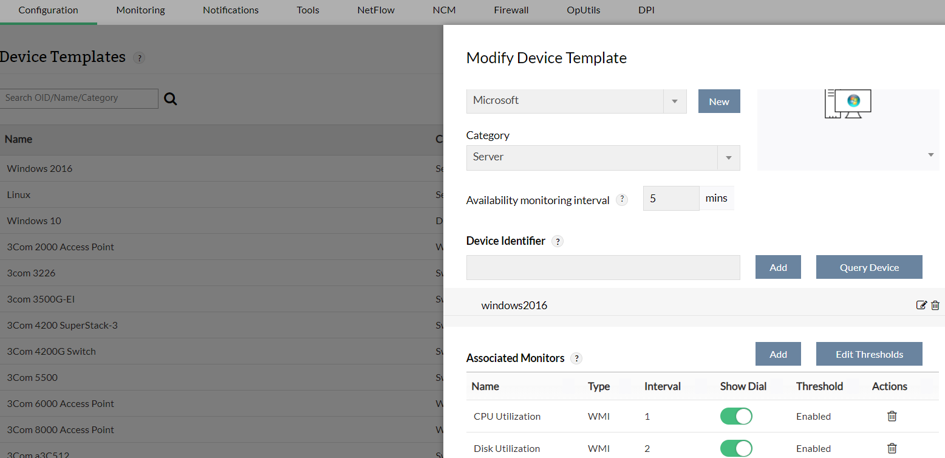
W tym widoku możemy dowolnie zmodyfikować:
- Domyślne monitory,
- Interwał odpytywania,
- Wartości brzegowe.
Pozwala to na spersonalizowanie aplikacji pod każdym kątem. Szablony urządzeń są szczególnie przydatne w przypadku przeskanowania sieci i automatycznej konfiguracji monitorowania urządzeń. Dzięki temu, możemy rozpocząć monitorowanie od razu po przeskanowaniu całej sieci, w podstawowym zakresie, a następnie doprecyzować wartości dla wybranych urządzeń.
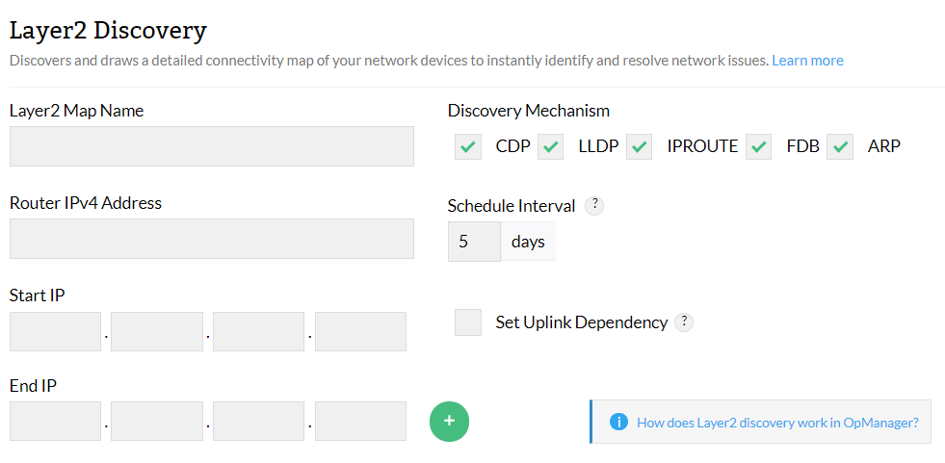
OPManager pozwala nam na zastosowanie wielu mechanizmów skanowania sieci, dzięki czemu mamy pewność, że nie pominiemy żadnego urządzenia.
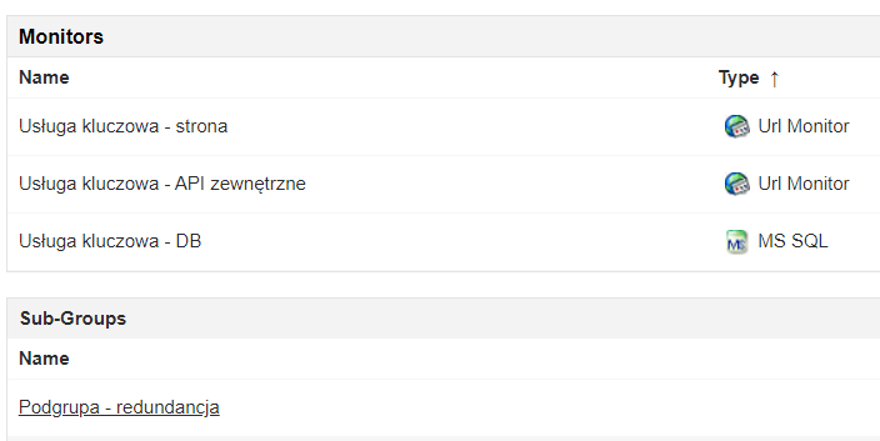
Elementem wiążącym wszystko, pod kątem monitorowania usługi kluczowej, jest grupowanie urządzeń. Pozwoli to nam na utworzenie zależności, między usługą a urządzeniami:

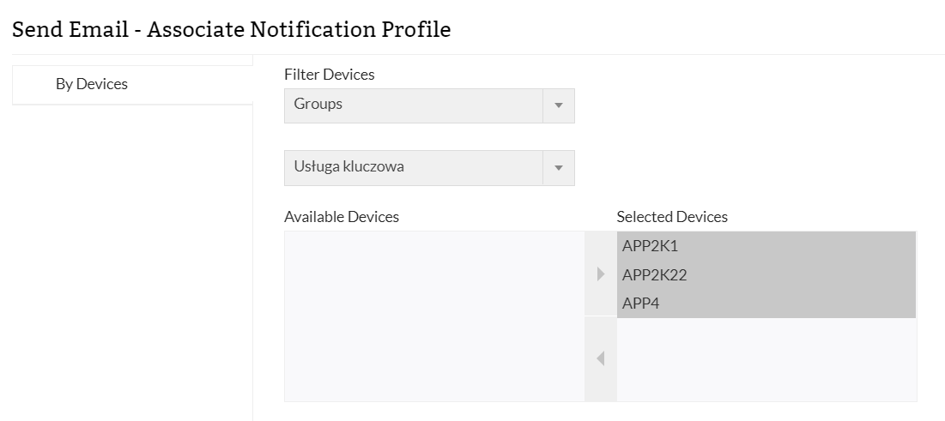
Dzięki skonfigurowaniu tej opcji, będziemy powiadamiani natychmiastowo, gdy tylko wystąpi problem z jakąkolwiek maszyną z grupy.
Opisane tu funkcje pozwolą nam na szybkie i bezproblemowe rozpoczęcia monitorowania strony fizycznej naszej usługi kluczowej. Dzięki możliwości ustawiania wartości brzegowych, alarmowania administratorów, konfiguracji ogólnych szablonów, szybkiego skanowania sieci oraz grup, możemy efektywnie podejść do wyzwania.
Drugim programem, który pomoże nam z wyzwaniem, będzie Applications Manager.
System pozwala na monitorowanie rozmaitych systemów, dzięki czemu mamy pewność, że będzie on odpowiadał naszym wymaganiom. Biorąc pod uwagę wcześniejszy przykład ze stroną internetową, załóżmy, że chcemy zbudować monitory wokół tej usługi.
Elementami do monitorowania byłyby:
- Strona Internetowa,
- Baza danych,
- Zewnętrzna usługa API, do przesyłania danych
- Serwery – które zostaną dodane do aplikacji, po uruchomieniu natywnej integracji z OPManagerem
ApplicationsManager pozwoli nam na szybkie skonfigurowanie monitorów tych instancji oraz powiązanie ich w grupę. Pierwszym etapem jest utworzenie monitora strony internetowej, na której wypełniamy formularz. Użyjemy monitora typu HTTP/HTTPs.
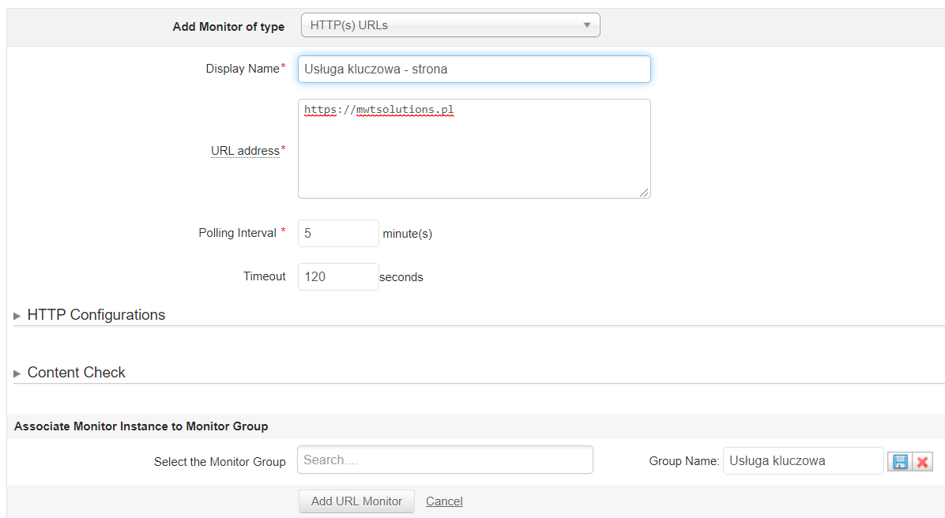
Należy wprowadzić odpowiednie dane, takie jak adres URL, interwał odpytywania oraz timeout po którym ma zostać zgłoszony problem. Applications Manager dodatkowo rozszerza możliwość weryfikacji strony o:
- Weryfikację strony pod kątem parametrów protokołu web,
- Weryfikację elementów na stronie.
Dodatkowo możemy również z poziomu monitora, stworzyć grupę, do której podłączymy kolejne monitory, wchodzące w skład danej usługi.
Dzięki możliwości parametryzacji protokołu web, mamy możliwość odpytania zewnętrznego API i weryfikacji odpowiedzi:
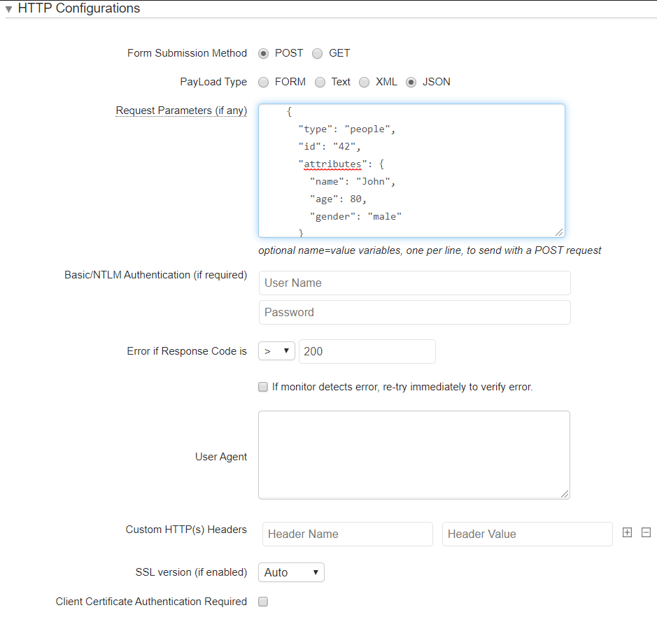
Mamy możliwość przesłania odpowiedniego zapytania, dzięki czemu przetestujemy API, pod kątem odpowiedzi przez usługę API. Możemy wybierać różne typy zapytania, w zależności od potrzeby.
System pozwala nam również na wykonanie prostej autentykacji NTLM’owej, dodania własnych nagłówków HTTP oraz wymuszenia specyficznego User Agent’a. Dzięki temu mamy możliwość monitorowania wymaganego API do poprawnego działania naszej usługi kluczowej.
Ostatnim monitorem, opartym na tym przykładzie, będzie monitor bazy danych.
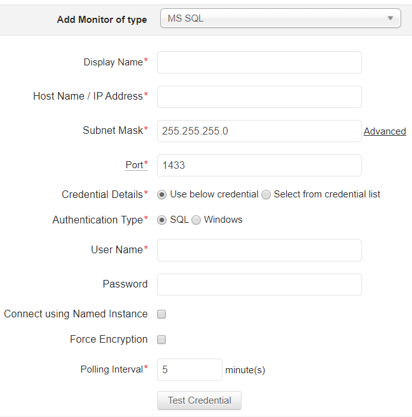
Applications Manager ułatwia nam jego dodanie, gdyż wymaga niewielu informacji, by móc go w pełni monitorować. Po jego dodaniu, aplikacja natychmiast zaczyna pobierać atrybuty z serwera bazodanowego i prezentuje je:

Również z tego poziomu, mamy możliwość konfiguracji odpowiednich wartości brzegowych oraz wykonywanych akcji.
Applications Manager pozwala również na rozbudowanie tych grup o różne podgrupy, dzięki czemu możemy odwzorować redundancję naszego środowiska. Stwórzmy zatem grupę, składającą się z dwóch serwerów. Serwery pojawiły się w wyniku integracji, między OPManagerem, a Applications Managerem, stąd też nie musimy ich dodatkowo konfigurować.

Następnie skonfigurujemy stan zdrowia podgrupy wtaki sposób, by awaria jednego sprzętu nie definiowała stanu krytycznego całej usługi.
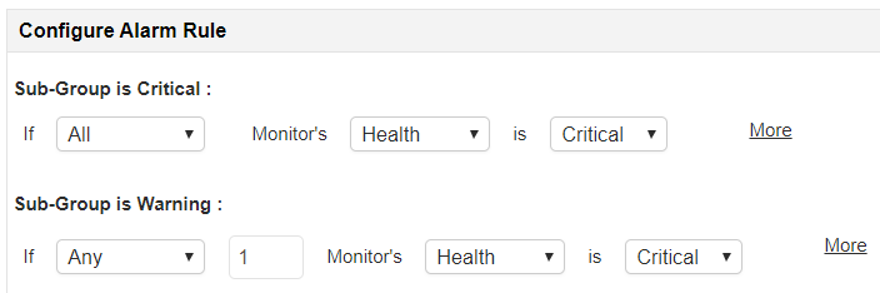
Dzięki temu, w przypadku awarii jednego z serwerów, aplikacja nie określi krytycznego stanu, a jedynie stan ostrzeżenie, dzięki czemu cała usługa kluczowa również nie zostanie oznaczona w stanie krytycznym.
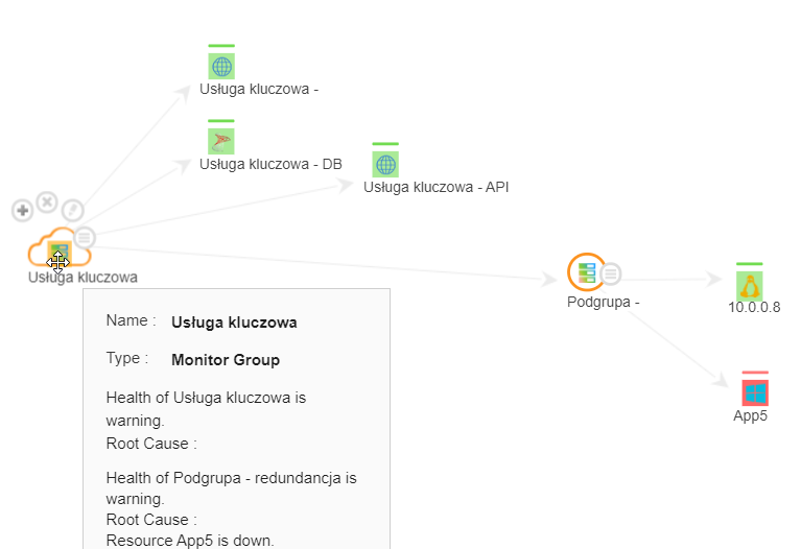
Po skonfigurowaniu wszystkich monitorów i dołączeniu ich do grupy, możemy ustawić alarm na całą grupę:
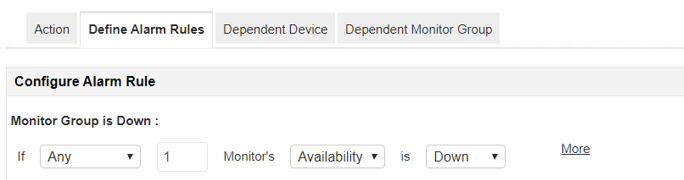
Gdy jedno z urządzeń (liczymy podgrupę w tym momencie jako urządzenie) będzie w statusie „Down”, mamy wtedy wyzwolić alarm.
Mamy również do wyboru inne opcje. Możemy również określić alarm na bazie statusów danej części, wszystkich lub wskazanych monitorów.

Następnie wybieramy akcje, które zostaną wykonane, po napotkaniu odpowiedniego statusu.
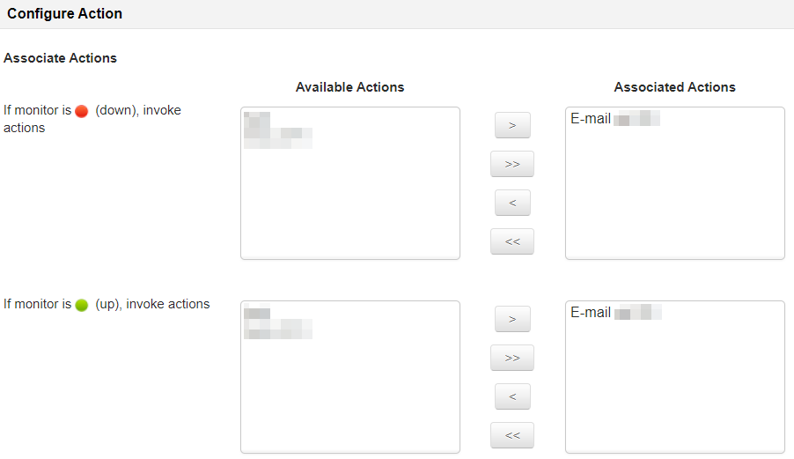
Możemy podłączyć wiele akcji do jednego alarmu, dzięki czemu możemy nie tylko wysłać e-maila, ale i uruchomić skrypt, który zmieni zawartość strony, by poinformowała użytkowników o przerwie technicznej.
Applications Manager generuje również widok biznesowy, dostępny pod zakładką „Business View”.
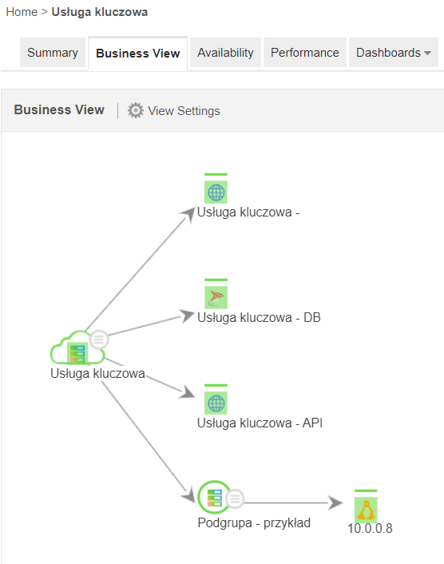
Widok ten może zostać umieszczony na zewnętrznej stronie Internetowej, poprzez prosty kod HTML’owy.
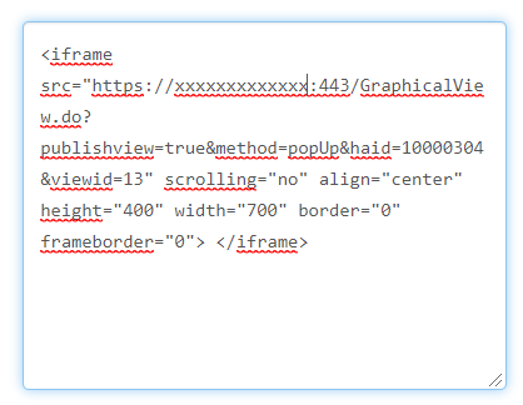
Dzięki takiemu zestawieniu aplikacji OPManager i Applications Manager, mamy pewność, że nasza usługa kluczowa będzie ciągle monitorowana, w wielu aspektach. Obie aplikacje pozwolą nam również na dogłębną weryfikację istoty problemu, dzięki czemu czas rozwiązania problemu zmniejszy się kilkukrotnie. Zamiast weryfikować każdy system po kolei, będziemy mogli przejść od razu do istoty problemu.
W kontekście obecnego oraz poprzedniego artykuł, należy wspomnieć o jednej z zalet naszych aplikacji. Potrafią one integrować się z systemami ITSM.
OPManager i Applications Manager pozwalają na natywną integrację z systemem ServiceDesk Plus.

Integracja pozwala na skonfigurowanie pól systemu ITSM. Dzięki temu, proces automatyzacji przypisania zgłoszenia po stronie ServiceDesk’a będzie efektywniejszy. Każdy alarm może posiadać zupełnie inną konfigurację pól. Możemy użyć przykładowych szablonów:
- Awaria serwera Windows -> Kategoria: Serwery, podkategoria: Windows, priorytet: średni
- Awaria kontrolera domeny -> Kategoria: Serwery, podkategoria: Windows, priorytet: najwyższy
- Awaria Access Pointa -> Kategoria: Urządzenia sieciowe, Podkategoria: AP; priorytet: średni.
Dzięki systemom ManageEngine OPManager oraz Application Manager możemy
w prosty sposób monitorować usługi kluczowe oraz wszelkie zmiany w nich zachodzące. Dodatkowa możliwość przypisywania zgłoszeń do systemu ITSM powoduje pełną kontrolę nad środowiskiem. W kolejnym artykule opiszemy sposób konfiguracji od strony ITSM. Wskażemy również, jak ważnym aspektem jest reagowanie na incydenty.
Masz pytania? Chcesz dowiedzieć się więcej? Skontaktuj się z nami!
04.02.2020
Autor: Stanisław Rogasik
Kategorie: Aktualności Artykuł


