



 pl
pl 




Wraz z pojawieniem się technologii chmurowych nastąpiła poważna zmiana w organizacjach w sposobie radzenia sobie z operacjami infrastrukturalnymi i świadczeniem usług. Coraz większe przekształcenia w kierunku platform opartych na chmurze, jak również hybrydowych ekosystemów, spowodowały, że zaczęto stosować narzędzia do monitorowania wspomnianych środowisk pod kątem wydajności i efektywności. W niniejszym artykule przedstawię korzyści płynące z kompleksowego monitorowania chmury. Podpowiem także, jak maksymalnie wykorzystać możliwości działających w jej obrębie serwisów.
Dlaczego warto zainstalować narzędzie do monitorowania chmury?
Jeżeli korzystamy z usługi chmury publicznej, takiej jak Amazon Web Services (AWS) lub Azure, prawdopodobnie używamy też systemu do monitorowania oferowanego przez danego dostawcę. Niewątpliwą zaletą takiego rozwiązania jest bezproblemowa integracja. Jednak w przypadku infrastruktury organizacyjnej o dużej skali, niezbędne stają się całodobowy nadzór nad platformą i widoczność wykraczająca poza podstawowe parametry. W przypadku struktury hybrydowej lub zbudowanych we własnym zakresie niestandardowych aplikacji, wysoce prawdopodobne jest, że proces sprawowania nad nimi kontroli będzie się komplikował wraz z ilością wprowadzanych narzędzi do różnych kluczowych technologii. W takiej sytuacji idealnym rozwiązaniem jest system do monitorowania środowiska, który może nadzorować serwery fizyczne i wirtualne wraz z usługami w chmurze. Pomoże zabezpieczyć cały ekosystem aplikacji IT przed niezauważonymi zagrożeniami na tle wydajności oraz wesprze w prognozowaniu jego wykorzystania.
Niektóre kluczowe parametry wśród popularnych usług monitorowania w chmurze:
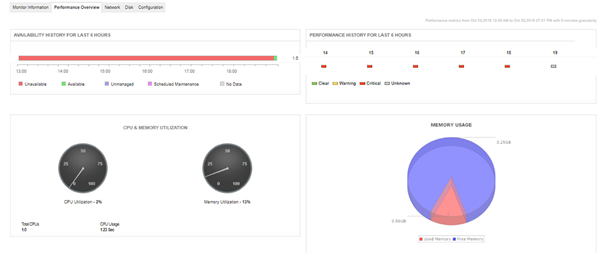
1. Compute: pamięć, dysk i sieć
Niezależnie od tego, czy używamy AWS, Azure, Oracle Cloud Infrastructure (OCI) czy Google Cloud Platform (GCP), Compute jest jedną z pierwszych usług wdrażanych przez organizacje. Monitorowanie wydajności wymienionych wcześniej rozwiązań odbywa się głównie poprzez śledzenie użycia pamięci, miejsca na dysku i ruchu w sieci. To kluczowe metryki dla zagwarantowania dostępności zasobów i bezproblemowej wydajności aplikacji. Historyczna analiza efektywności tych trendów wykorzystania może pomóc w planowaniu sprawności na przyszłość.
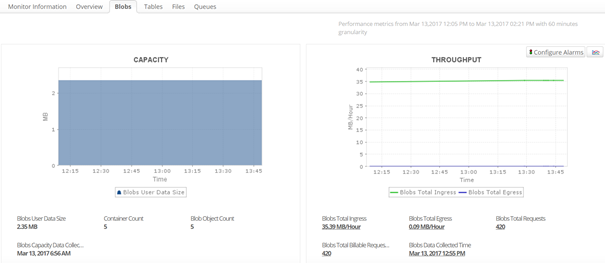
2. Object Storage: całkowita liczba obiektów, rozmiar obiektów, żądania na minutę i ruch sieciowy
W zależności od dostawcy, metryki pamięci blokowej mogą się różnić, ale są to mniej więcej te same parametry. Obiekty, rozmiar obiektów, liczba zgłoszeń na minutę, szczegóły sieci i opóźnienia są krytycznymi wskaźnikami monitorowania chmury AWS, GCP i OCI. W przypadku Azure są nimi natomiast żądania i rozmiar obiektów blob. Te aspekty mogą pomóc zrozumieć obciążenie usługi pamięci masowej i zidentyfikować nieprawidłowości w przetwarzaniu wymogów, wskazując błędne obszary.
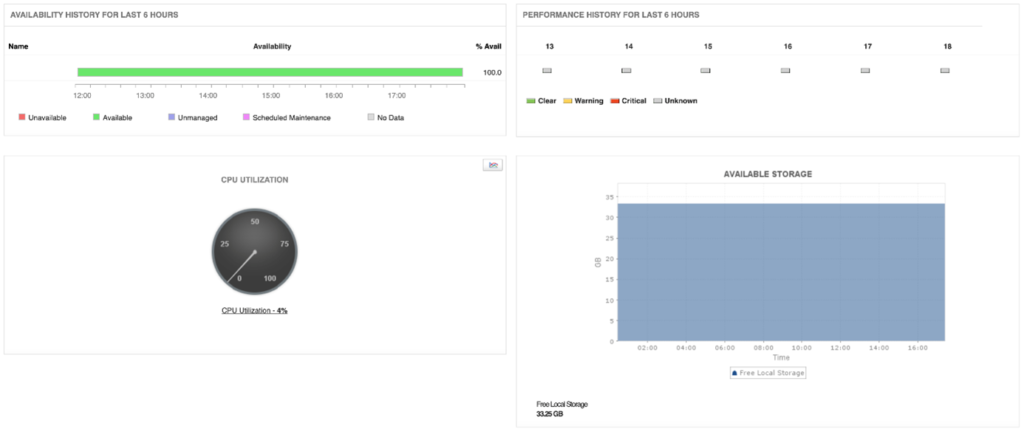
3. Relational Database: wykorzystanie procesora, przestrzeń dyskowa, połączenia z bazami danych i opóźnienia w sieci
Relacyjne bazy danych zawsze były popularne wśród programistów i są szeroko stosowane w przedsiębiorstwach. Podobnie jak w przypadku konfiguracji fizycznych, archiwa danych w chmurze wymagają również kontroli. Zwłaszcza pod względem wskaźników, takich jak wykorzystanie procesora, sesje oraz połączenia bazy danych czy też szczegóły obszaru tabel. Głębokie monitorowanie z odpowiednimi progami jest kluczowe podczas kontroli wspomnianych źródeł. Możemy uniknąć wtedy problemów z obniżeniem wydajności, jak na przykład zwiększony czas odpowiedzi aplikacji dla użytkowników końcowych – powodowany rosnącą liczbą generowanych przez nich sesji lub powolnego wykonywania zapytań.
Wdrażanie odpowiedniego planu monitorowania chmury
Monitorowanie dowolnego komponentu IT, począwszy od serwerów fizycznych przez usługi w chmurze po aplikacje dla użytkowników końcowych, wymaga dużej widoczności. Dzięki niej możemy spostrzec wiele elementów, które ujawniają podstawowe problemy wydajnościowe. W przeciwnym razie, pozostałyby one niezauważone dając o sobie znać dopiero przy spadku efektywności czy przestojach w działaniu.
Monitorowanie najważniejszych elementów
Szczególnie ważną kwestią jest upewnienie się, że nadzorowane są wszystkie istotne elementy ekosystemu IT. Zwłaszcza podstawy, takie jak infrastruktura serwerowa (fizyczna, wirtualna lub w chmurze) oraz wydajności sieci i aplikacji. Można to osiągnąć dzięki kompleksowemu systemowi do monitorowania, który zapewnia bogaty wgląd w problemy z wydajnością, a także ułatwia jej planowanie poprzez analizę trendów historycznych.
Bez względu na dostawcę chmury, z którego korzystamy, nie mając szczegółowego wglądu w krytyczne parametry zawsze będą czaiły się problemy z wydajnością, a bezproblemowe świadczenie usług biznesowych będzie zagrożone.
Monitorowanie infrastruktury w chmurze i lokalnej z jednego pulpitu nawigacyjnego
Ponieważ nowoczesne organizacje powoli przechodzą w kierunku ekosystemu opartego wyłącznie na chmurze lub hybrydzie, należy upewnić się, że narzędzie do weryfikacji tego obszaru oferuje jeden pulpit nawigacyjny do gromadzenia i korelowania danych z elementów fizycznych, wirtualnych i chmurowych. Ta elastyczność sprawi, że zmiana będzie łatwa i obsłużone zostaną również starsze aplikacje i serwery fizyczne. Obejmiemy tym sposobem cały ekosystem IT i sprawimy, że wdrożenie aplikacji nadzorującej chmurę będzie opłacalną inwestycją.
Automatyzacja rutynowych zadań naprawczych
Automatyzując powtarzające się zadania naprawcze, możemy skupić się na sytuacjach, które wymagają interwencji człowieka. Proces ten jest istotną częścią działań DevOps. Zdefiniowanie odpowiedniego mechanizmu może pomóc w zwiększeniu produktywności w chmurze. Można na przykład skonfigurować automatyczne akcje, takie jak uruchamianie, zatrzymywanie lub ponowny start instancji chmury, gdy zostanie przekroczony konkretny próg. Pomaga to w wykonywaniu działań związanych ze skalowaniem lub automatycznym zamykaniem nieużywanych zasobów i lepszym zarządzaniu kosztami chmury. Zwłaszcza, gdy korzystamy z planu cenowego płatności zgodnie z rzeczywistym użyciem.
Zarządzanie kosztami
Ciągłe korzystanie z usług na platformie chmurowej może często zwiększyć koszty. Oczywiście możemy posiadać miesięczne budżety na tego typu wydatki. Jednak idealne narzędzie do monitorowania jej wydajności powinno mieć możliwość śledzenia rozliczeń i powiadamiania w przypadku osiągnięcia określonej kwoty progowej. Uzyskamy tym sposobem informacje o wykorzystaniu i odpowiednich trendach kosztowych, dzięki temu zaplanujemy odpowiednio budżet.
Narzędzie do zarządzania wydajnością aplikacji Applications Manager oferuje dogłębne monitorowanie chmury hybrydowej – od serwerów fizycznych i wirtualnych przez popularne usługi chmurowe w ramach AWS, Azure, GCP, OCI, OpenStack, do usług SaaS, takich jak Office365 i ponad 130 innych aplikacji biznesowych. Zapewnia pełny wgląd w ekosystem aplikacji IT. Umożliwia konfigurowanie automatycznych alertów i podejmowanie działań zaradczych. System ten pozwala też lepiej zrozumieć ogólną dostępność i wydajność, ułatwia planowanie zdolności, dzięki której jesteśmy w stanie dostarczać klientom płynnie działające usługi.
15.07.2021
Autor: marketing@mwtsolutions.eu
Kategorie: Aktualności Artykuł


