
W nowoczesnych środowiskach IT jedna drobna awaria potrafi w kilka sekund wygenerować dziesiątki alarmów. Serwery, aplikacje i usługi zaczynają zgłaszać problemy, a zespół IT zamiast szybko zlokalizować przyczynę, musi przedzierać się przez „szum informacyjny”. Bez mechanizmów korelacji zdarzeń zespoły IT często reagują na skutki awarii, a nie na jej rzeczywistą przyczynę. Efekt? Wydłużony czas reakcji, niepotrzebne eskalacje i frustracja użytkowników.
Właśnie w takich sytuacjach kluczowe znaczenie ma Root Cause Analysis oraz inteligentne alertowanie. W tym artykule pokazujemy, jak OpManager Plus pomaga odróżnić objawy od rzeczywistej przyczyny awarii, ograniczyć liczbę alertów i szybciej przywrócić stabilność sieci – bez zgadywania i ręcznej analizy logów.
1. Alert flood vs. prawdziwa przyczyna awarii – dlaczego jeden problem generuje dziesiątki alarmów i jak OpManager Plus to porządkuje
W klasycznym monitoringu awaria jednego elementu sieci bardzo szybko prowadzi do tzw. alert flood (jeden problem generuje jednocześnie bardzo dużą liczbę alertów w systemie monitoringu). Każdy z tych alarmów traktowany jest jako niezależny incydent, przez co administratorzy są zmuszeni do ręcznej analizy zależności między urządzeniami. Gdy przestaje odpowiadać przełącznik agregacyjny, serwery podłączone do niego zaczynają zgłaszać brak łączności, aplikacje raportują niedostępność usług, a system monitoringu wysyła dziesiątki alarmów opisujących ten sam problem z różnych perspektyw.
Jak sprawdzi się tu OpManager Plus?
W środowisku z kilkudziesięcioma serwerami podłączonymi do jednego switcha OpManager Plus wykrywa brak odpowiedzi przełącznika jako zdarzenie pierwotne. Jednocześnie rozpoznaje, że alarmy z serwerów są zdarzeniami wtórnymi wynikającymi z tej samej przyczyny. Zamiast kilkudziesięciu powiadomień administrator otrzymuje jeden, priorytetowy alert wskazujący konkretny element sieci odpowiedzialny za awarię.
Co zyskujesz?
W praktyce oznacza to, że zespół IT od razu wie, gdzie szukać problemu, a czas diagnozy i usunięcia usterki zostaje znacząco skrócony.
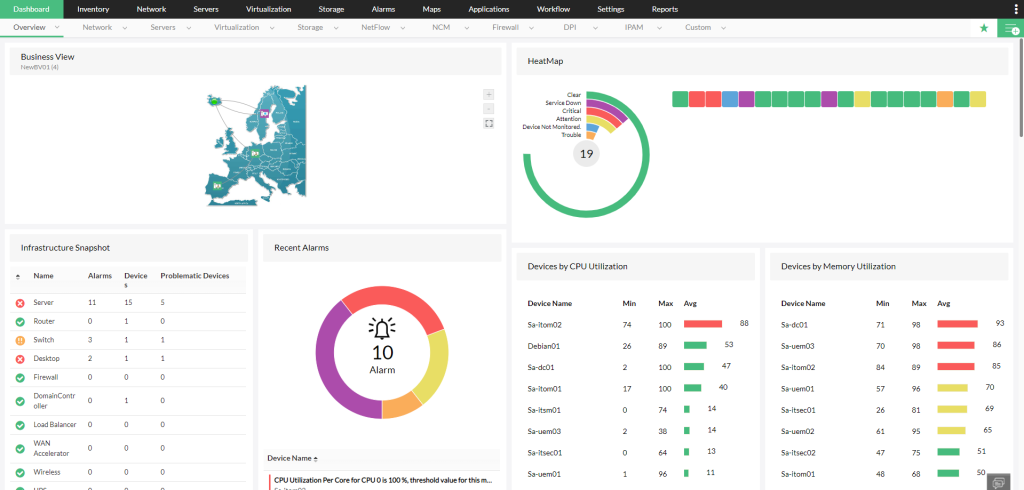
Przedstawienie korelacji oraz kategoryzacji alertów w aplikacji OpManager Plus.
2. Inteligentne alertowanie zamiast fałszywych alarmów – dlaczego statyczne progi zawodzą i jak OpManager Plus uczy się normalnego zachowania sieci?
Jak sprawdzi się tu OpManager Plus?
W środowisku, w którym regularnie wykonywane są nocne kopie zapasowe, OpManager Plus analizuje historyczne dane wykorzystania pasma i zasobów. System rozpoznaje, że podwyższone obciążenie w określonych godzinach jest zjawiskiem normalnym i nie generuje alarmu. Alert pojawia się dopiero wtedy, gdy ruch lub obciążenie znacząco odbiega od ustalonego wzorca, co pozwala reagować tylko na zdarzenia, które faktycznie wymagają interwencji zespołu IT.
Co zyskujesz?
Dzięki adaptacyjnym progom alarmowym administratorzy otrzymują mniej powiadomień, ale o znacznie większej wartości diagnostycznej.
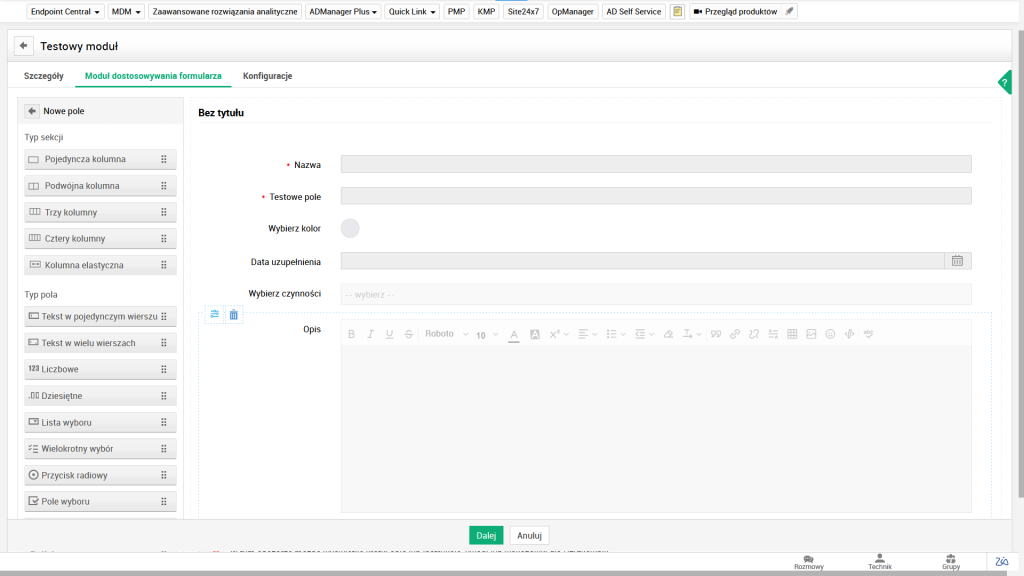
Interfejs konfiguracji adaptacyjnych progów (Adaptive Thresholds) – pokazuje panel, w którym możesz skonfigurować progi oparte na analizie historycznej, zamiast statycznych wartości.
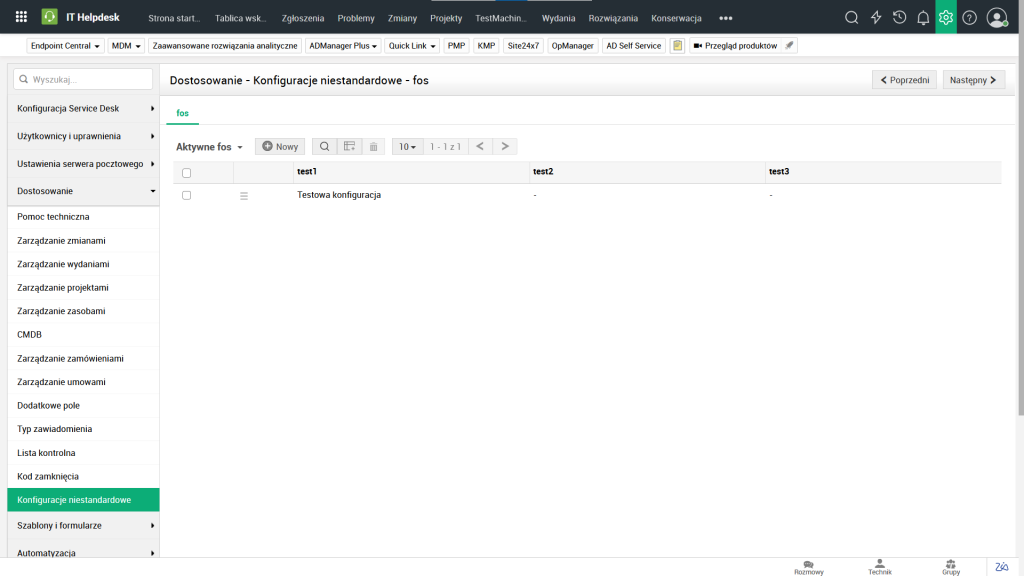
Ustawienia wartości progów i odchyleń, które system wykorzystuje, aby nauczyć się „normalnych” zachowań sieci, co skutkuje mniejszą liczbą fałszywych alarmów.
3. Priorytetyzacja incydentów z perspektywy biznesowej – jak OpManager Plus wskazuje to, co naprawdę krytyczne
Jak sprawdzi się tu OpManager Plus?
W infrastrukturze, w której działa zarówno środowisko produkcyjne, jak i systemy pomocnicze, OpManager Plus uwzględnia typ urządzenia, jego rolę oraz zależności usług. Gdy jednocześnie pojawia się alarm z serwera testowego oraz problem z łącznością do systemu ERP, OpManager Plus automatycznie oznacza incydent dotyczący ERP jako krytyczny. Administrator od razu widzi, że problem wpływa na kluczowy proces biznesowy, a nie tylko na zasób techniczny o niskim znaczeniu operacyjnym.
Co zyskujesz?
Rezultatem jest, że zespół IT może skupić się na incydentach, które realnie wpływają na biznes, skracając czas niedostępności usług i poprawiając komunikację z użytkownikami oraz kadrą zarządzającą.
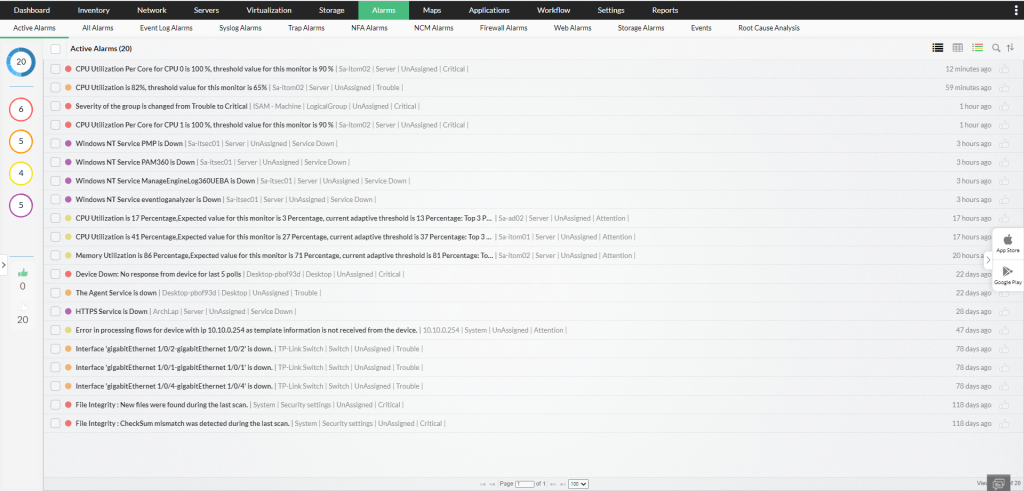
Zrzut ekranu pokazuje dashboard OpManager Plus, gdzie alarmy są automatycznie priorytetyzowane według wpływu na kluczowe procesy biznesowe, dzięki czemu administrator natychmiast widzi, które problemy są krytyczne dla organizacji.
4. Jak to działa w praktyce? Mechanizm korelacji zdarzeń i Root Cause Analysis w OpManager Plus
Kluczowe możliwości
OpManager Plus łączy korelację zdarzeń, adaptacyjne alertowanie i kontekst biznesowy, dzięki czemu zespoły IT mogą szybciej identyfikować przyczyny awarii i reagować adekwatnie do ich wpływu na organizację. Zamiast walczyć z nadmiarem alarmów, administratorzy skupiają się na realnych problemach i ciągłości działania usług.




















